当我们能使用match来搜索匹配数据的时候,es会给每一个文档进行评分(匹配度),并根据评分的大小对结果文档进行排序。
介绍
es的实时评分机制是基于 Lucene 的基础上实现的,最常见的是 TF/IDF和BM25这两种评分模型。
TF-IDF属于向量空间模型,而BM25属于概率模型,但是他们的公式可能并没有你想象的那么大差距。两种相似度模型都使用idf方法和tf方法的某种乘积来定义单个词项的权重,然后把和查询匹配的词项的权重相加作为整篇文档的分数。
对于这两种算法的详细介绍以及区别大家可以参考:
在es5.0版本之前使用了TF/IDF算法实现,而在5.0之后默认使用BM25方法实现。
作为开发,我们可以不需要了解非常深入的了解公式的由来,但也要做到公式的组成和每个参数的含义。
例子
下面是一个普通的查询:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19PUT /test/test1/1
{"title":"hallo,books"}
PUT /test/test1/2
{"title":"hallo,books boy"}
PUT /test/test1/3
{"title":"hallo hallo,hi hi hi hi"}
PUT /test/test1/4
{"title":"hallo hallo,hi hi hi hi"}
PUT /test/test1/5
{"title":"hi hi hi hi"}
GET /test/test1/_search
{
"query": {
"match": {
"title": "hallo hi"
}
}
}
在搜索的结果中有一个_score字段,代表了es给文档的评分,默认的排序规则是根据这个字段的大小进行排序,越大则出现在越前面。
当我们搜索一个单词或者一个词组乃至一句话的时候,es先会通过Analyzer分析器拆成多个term(ES学习——分析器和自定义分析器),然后在对每一个term进行BM25公式评分,最后把每一个term的评分进行加权求和,就是最后的得分。
例如,我们搜索hallo hi,es通过对应的默认解析器拆分成hallo和hi,分别求出分数score(hallo)和score(hi):
总得分Score=score(hallo)+score(hi)。
和sql相似,我们可以通过在搜索条件中添加explain=true,来查看具体的得分过程。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81GET /test/test1/_search?explain=true
{
"query": {
"match": {
"title": "hallo hi"
}
}
}
##以下通过筛选,过滤了一些无用的信息
{
"_shard": "[test][0]",【1】
"_score": 1.202173,【2】
"_source": {
"title": "hallo hallo,hi hi hi hi"【3】
},
"_explanation": {
"value": 1.202173,
"description": "sum of:",【4】
"details": [
{
"value": 0.3530123,【5】
"description": "weight(title:hallo in 2) [PerFieldSimilarity], result of:",
"details": [
{
"value": 0.3530123,【7】
"description": "score(doc=2,freq=2.0 = termFreq=2.0\n), product of:",
"details": [
{
"value": 0.2876821,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details": [
{
"value": 4,
"description": "docFreq"
},
{
"value": 5,
"description": "docCount"
}
]
},
{
"value": 1.2270917,【8】
"description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",
"details": [
{
"value": 2,
"description": "termFreq=2.0"
},
{
"value": 1.2,
"description": "parameter k1"
},
{
"value": 0.75,
"description": "parameter b"
},
{
"value": 4.2,
"description": "avgFieldLength"
},
{
"value": 6,
"description": "fieldLength"
}
]
}
]
}
]
},
{
"value": 0.84916073,【6】
"description": "weight(title:hi in 2) [PerFieldSimilarity], result of:"
##省略和 hallo的计算方式类似
}
]
}
}
从最外层结构往里分析:
【1】:代表文档的分片,[test][0],在es中每一个分片评分都是单独计算的
【2】【3】:代表最后的分数和文档
【4】:总的分数是1.202173,sum of是默认的加权平均,把hallo的分数(0.3530123)+hi的分数(0.84916073)
【5】【6】:分表表示hallo的评分和hi的评分。其description描述的很明白:weight(title:hallo in 2)
【7】【8】:hallo的评分是由【7】(idf)【8】(tfNorm)得出
【7】:idf(下面介绍)=log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5))
【8】:tfNorm=`(freq (k1 + 1)) / (freq + k1 (1 - b + b fieldLength / avgFieldLength))`
公式介绍(BM25)
归纳一下上面的公式:
$$score = \Sigma(IDF*tfNorm)$$
IDF (inverse document frequency):逆文档频率,是指一个词在文档中出现的次数越多,则他的权值相对越多。例如常用的词and 或 or 或 a在文档中出现的次数非常多,相对于用户而言重要性很小,但是elasticSearch等不常见的词进行搜索的时候相对于用户来说,权重应该更大。
IDF
在_explanation中也已经写明了IDF的计算公式:
$$
IDF = \log(\frac{1 + (docCount - docFreq + 0.5)}{docFreq + 0.5})
$$
其中docCount代表该分片总的文档数量数量,docFreq代表有这个分词的文档数量。
在例子中,总共的文档数为5,包含hallo的文档数为4,所以docFreq=4,docCount=5。IDF最终算出来为0.2876821,且在同一分片中所有的文档的IDF且相同。
tfNorm
tfNorm代表此term在此文档中的重要程度,在此doc中出现次数越多,越重要;并且文档的长度越短,也见解说明改term在此doc中越重要。
具体公式: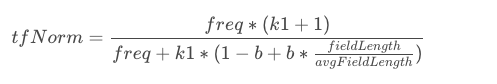
其中:
freq:在文档中出现的次数
k1:为调优参数,固定值,默认1.2,合理的值需要依赖文档的数据。
b:为调优参数,固定值,默认为0.75,合理的值需要依赖文档的数据。
fieldLength:是满足查询条件的doc的filed的长度
avgFieldLength:是满足查询条件的所有doc的filed的长度.
注意点
评分都是以分片为单位的,若两个文档分布在不同的分片,会出现即使内容完全相同但是分数有差异的情况(IDF的docCount和docFreq有区别)或者出现更加符合我们心里预期的文档分数反而较低的情况。
方案:
- 把结构相似的文档通过route到一个分片上。个人认为若文档种类差异较大可以使用这种方法,但是会出现分片数据不均匀的问题。
- 自定义评分处理。有公式看出IDF只与出现次数和文档总数有关,在一个分片中,次数和文档总数是固定的,在全局中也是一样。 设置忽略IDF。 但是这种方法,在多个term查询的时候,相当于忽略了IDF对分数的影响。
- 业务上可以容忍,不做修改。当文档的基数很大,且文档分配很均匀的时候,两个相同的文档分数的差异会相对减少。